
ASCOMP Text-R 是一款轻量且易于使用的 OCR 文字识别软件,可从 PDF 或图片文件中精准提取文字,适用于办公整理、资料录入与文档编辑等场景。软件支持英语、德语、法语、意大利语、丹麦语、保加利亚语、克罗地亚语等多种常见语言,识别率稳定可靠。借助向导式操作流程,用户只需选择文件、设定语言与识别选项即可完成处理,并可将识别结果快速复制或保存。凭借其简洁界面与OCR工具 的多语种优势,能够满足跨语言文本提取需求,同时PDF识别 模块也为复杂文档转换场景提供便捷支持。
# 新版变化
http://www.text-r.com/changelog_en.txt
Changes in v2.011
- Improved licensing
# 软件特点
- 支持多语种 OCR 识别,适合跨语言资料整理与文本转换需求。
- 操作流程简单,通过向导式界面即可快速完成识别任务。
- 对 PDF 与图片文件均具备良好识别率,适用于多类文档处理场景。
- 界面简洁直观,新手也能轻松上手,无需复杂配置。
- 输出灵活,可直接复制、保存或应用识别文本,提高工作效率。
# 功能特性
- 多语种识别:支持十数种常见语言,满足跨语言文档提取需求。
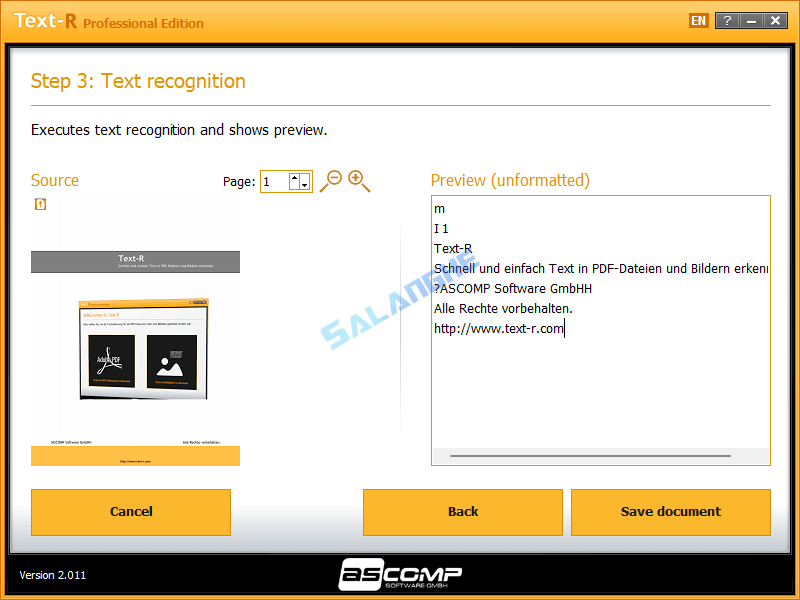
- PDF 提取:从扫描件或数字 PDF 中高精度抽取文字内容。
- 图片 OCR:支持 JPEG、PNG、BMP 等格式的图片文字识别。
- 向导式操作:通过步骤引导方式完成文件选择与语言设置。
- 批量处理:可一次处理多个文件,适合高频文档工作场景。
- 结果导出:识别文本可快速复制或保存为多种格式。
- 语言自动识别:根据文件内容智能判断可能语言,提高识别效率。
- 文本校正:提供基础校对功能,便于用户优化最终结果。
- 高精度引擎:基于先进 OCR 技术保证识别质量与稳定性。
- 轻量运行:占用资源低,适合长期在电脑后台使用。

